
Different types of data and their corresponding plots will have different requirements and needs, but there are a set of best practices that apply across most visualizations. These include:
Resources for different areas of best practices in data viz are linked below:
Examples
Here's an example from the first blog linked below, "Five qualities of great visualizations". The plot on the left is poorly designed; the plot on the right is cleaned-up.
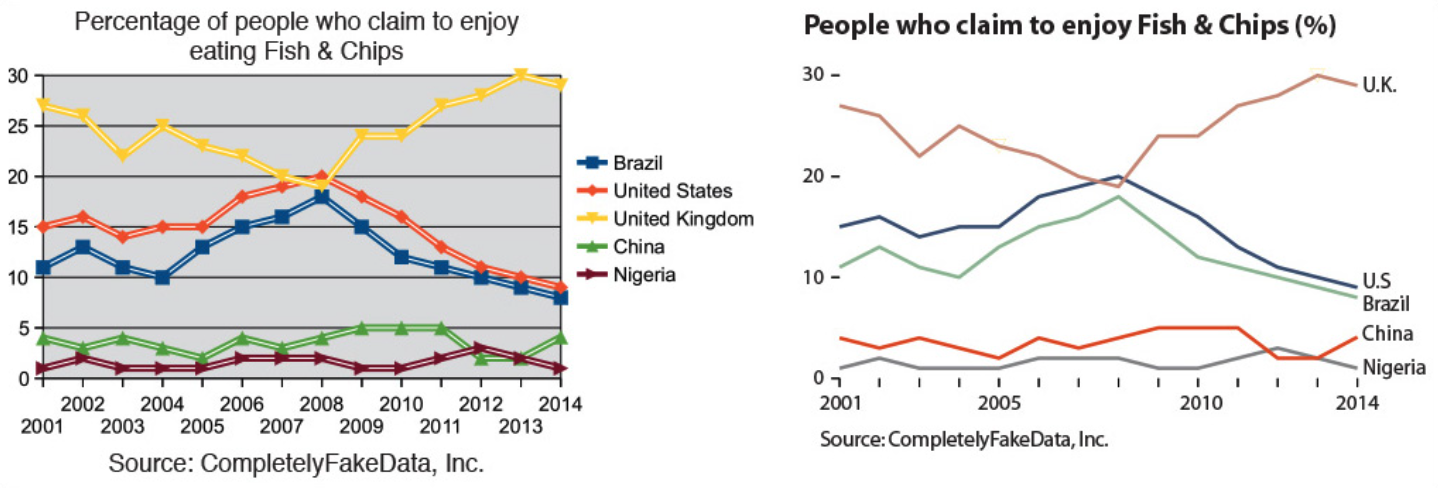
Notice:
Here's a second example, with a more complex plot and no "bad" comparison.
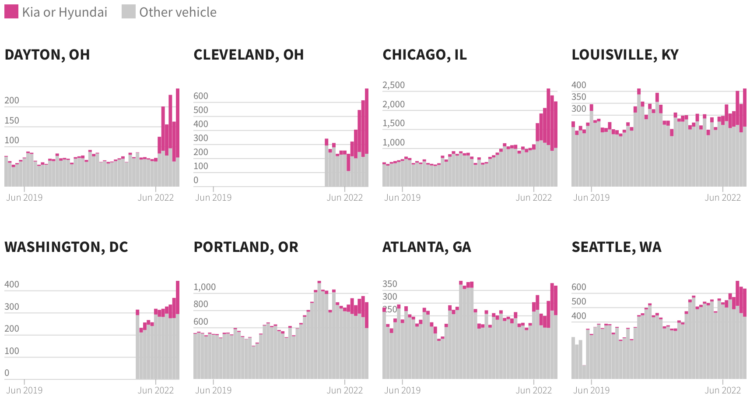
We're looking at a grid of 8 stacked bar plots. Stacked bar plots let us compare a few numerical categorical variables across There are several things to notice:
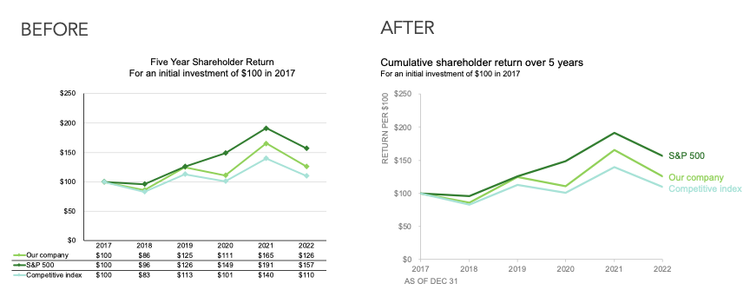
A third example is the blog post "what clutter can we eliminate?" by Elizabeth Ricks on the blog storytellingwithdata.com.
Ricks shows the process of improving a "cluttered" and difficult to read plot, incrementally making changes to remove extraneous elements and make a plot easier to grasp the meaning of. Note that what may be "clutter" for one visualization may be very important for another! In this case, however, Ricks' example visualization aims at being quickly and clearly understandable.
Camm, J. D., Fry, M. J., & Shaffer, J. (2017). A Practitioner’s Guide to Best Practices in Data Visualization. Interfaces, 47(6), 473–488. https://doi.org/10.1287/inte.2017.0916
Midway, S. R. (2020). Principles of Effective Data Visualization. Patterns, 1(9), 100141. https://doi.org/10.1016/j.patter.2020.100141
Rougier, N. P., Droettboom, M., & Bourne, P. E. (2014). Ten Simple Rules for Better Figures. PLOS Computational Biology, 10(9), e1003833. https://doi.org/10.1371/journal.pcbi.1003833
Alt text for data viz
Colorblindness-checking tools